По трём операциям в банкомате предскажу размер вашего дохода. И помогут в этом Big Data. Не то, чтобы меня интересовал баланс, валюта счёта или тип карты. Достаточно знать времена и даты подхода к железному кассиру. В дело вступят модели, разработанные на миллионах сограждан и иностранцах.

Мечта бизнеса – знать долю в кошельке клиента. Так можно понять уровень приверженности, рассчитать коэффициент возвращаемости и меру перспективности. Система лояльности такой роскоши предоставить не может: да, картой воспользовались, но ей ли одной? Как в неприличной шутке:
– Дорогая, я у тебя первый?
– Милый, сегодня или вообще?
Не пугайтесь, но кроме дохода, велика вероятность угадать ваш пол, возраст, род занятий и удалённость проживания от места работы. Все данные, доступные банку, ежесекундно работают против вас. Плохо это или хорошо, этично или аморально – разберёмся за пределами публикации. Тут – исключительно факты.
Принципы работы с данными:
- Используем эмпирическую модель – основывается на фактических данных, без теоретических предположений и предварительных гипотез.
- Создаём выборку клиентов с известными доходами (сотрудники и зарплатные клиенты): обучающая – 70%; тестовая – 30%.
- Прогноз дохода основывается на размере и структуре фактических расходов на годовом горизонте с платежных карт, эмитированных банком.
Порядок создания и применения модели:
- Создать выборку операций за последние или желаемые к анализу 12 месяцев.
- Исключить из списка транзакций неинформативные записи:
- отказ от операции
- нулевые суммы
- возврат денег.
- Определить товарные направления транзакций по одной, двум (для крупных товарных направлений) цифрам кода МСС.
- Сгруппировать массив транзакций до поклиентного уровня.
- Найти общую годовую сумму транзакций по отдельному Клиенту, разделенную по товарным направлениям.
- Структурой распределения сумм по товарным направлениям сформировать индивидуальные профили расходов Клиента.
- Рассчитать типовые профили:
- исключить Клиентов с неизвестным доходом.
- отобрать обучающую выборку Клиентов для построения типовых профилей расходов.
- определить обобщенные профили расходов путем объединения похожих в один. Степень обобщения определить максимальным покрытием пространства профилей и минимизацией вариации дохода в пределах обобщенного профиля.
- клиентов сгруппировать по типовым профилям расходов. В пределах профилей рассчитать: количество клиентов, средний доход и его стандартное отклонение.
- Клиентские профили расходов из тестовой выборки сравнить с типовыми профилями расходов. Клиентам тестовой выборки присвоить расчетное значение среднего дохода типового профиля.
- В тестовой выборке соотнести значения реального дохода и расчётного по модели типовых профилей расходов. Определить отклонения в предсказаниях и точность модели.
- На основании распределений и статистик отклонений прогноза предложить корректирующую поправку, устраняющую систематическую ошибку в предсказаниях.
- Уточненную модель применить к Клиентам с неизвестным доходом, предсказывая вероятный доход.
Найденная система уравнений показала ниспадающую точность, отражённую на Рис.1. В предсказаниях возникала систематическая ошибка, связанная с отсутствием нормального распределения доходов по клиентам. До Ᵽ 80 К значения систематически завышались, после Ᵽ 100 К – систематически занижались.

Рис. 1. Первичная модель предсказания доходов клиентов.
Пришлось добавить корректирующее уравнение, нивелирующее систематические ошибки. Отклонения стали группироваться вдоль оси – сумма погрешностей устремилась к нулю – Рис. 2.
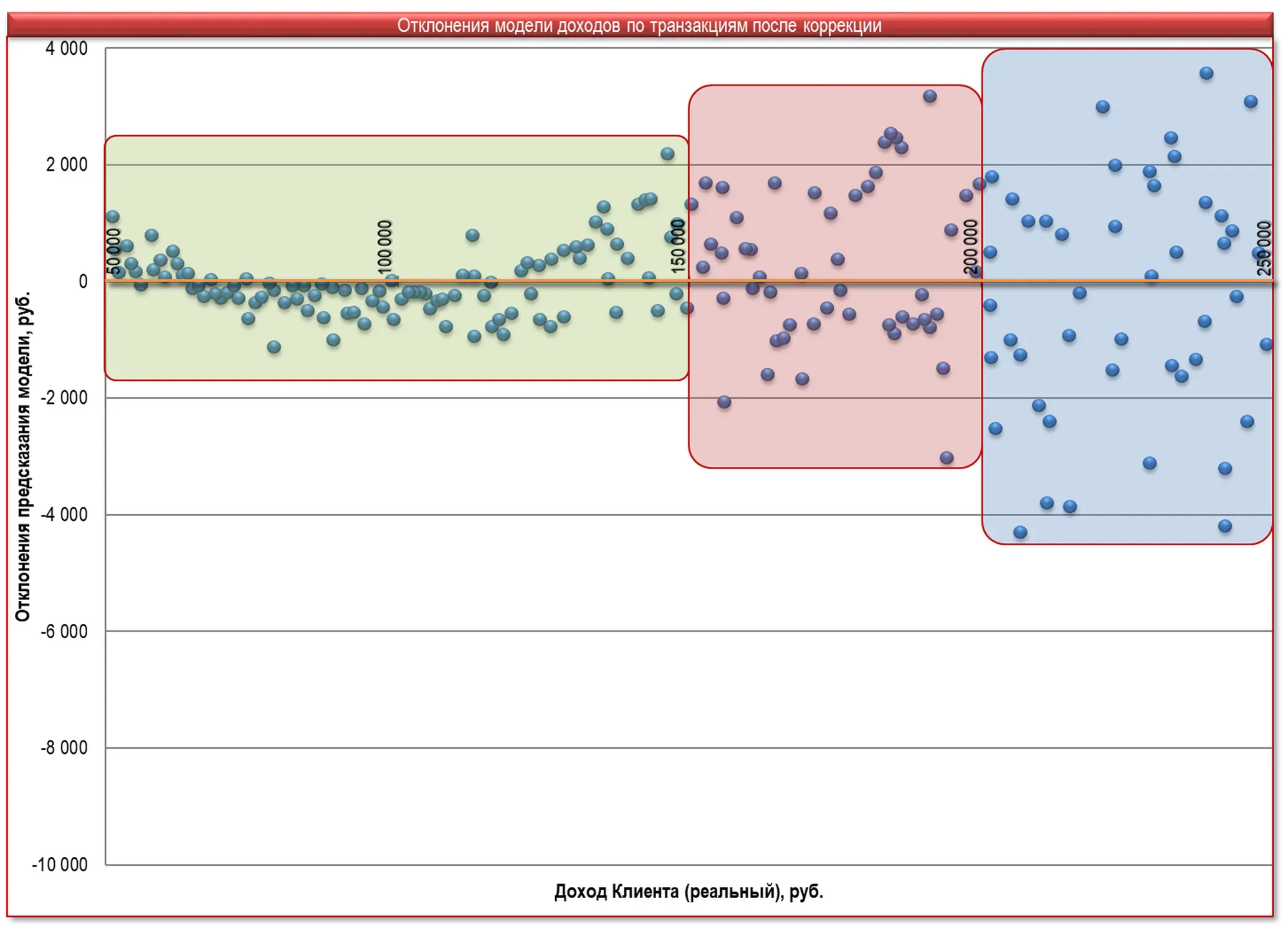
Рис. 1. Вторичная, скорректированная модель предсказания доходов клиентов.
В процессе развернутого анализа модели были выявлены особенности взаимосвязи модели и потребительского поведения клиентов:
- Если у Клиента расходы значительно превышают доход – модель предсказывает завышенный результат – срабатывает фактор «дополнительных поступлений».
- Если доходы существенно превышают расходы – модель занижает предсказание – вероятно накопление «депозита».
Поэтому возникает дополнительная зависимость – Рис. 3.
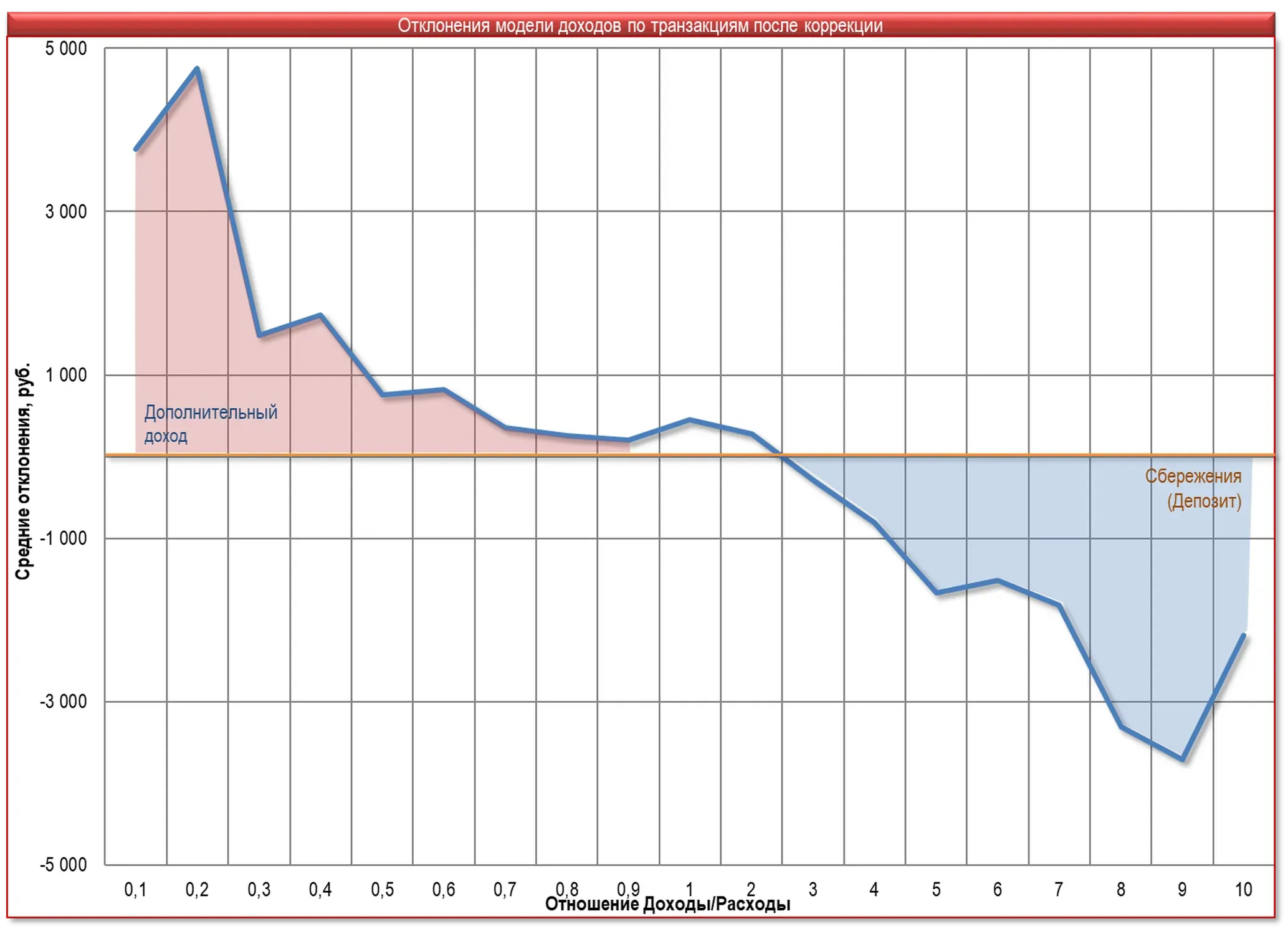
Рис. 3. Модель вычисления дополнительных поступлений или вывода денег на сберегательные счета.
Оттрактуем полученные результаты, опустив незначительные технические подробности:
- Структура и размер расходов (профиль расходов) клиента эффективно описывает уровень его дохода. Введение других показателей о платежных картах или транзакциях клиента не смогли значимо повлиять на точность моделирования и качество предсказания.
- Модель эффективно работает в целевом диапазоне Ᵽ 50 К – 250 К. Для более низких значений доходов велика относительная погрешность предсказаний (более 50%). В более высоком диапазоне доходов увеличивается доля клиентов, для которых модель не может дать предсказания из-за разрывов в типовых профилях обучающей выборки. Клиенты с высокими доходами редки, имеют уникальные профили, чего недостаточно для полного перекрытия пространства доходов. Со временем, в процессе дообучения модели и накопления исторических данных, количество и полнота типовых профилей увеличивается.
- Среднее отклонение в предсказании дохода нового клиента по профилю транзакций составляет 30%. Для существующего клиента (входит в обучающую выборку) среднее отклонение составляет 6%. Модель рекомендуется использовать только в офлайн режиме.
- Значительные отклонения вверх (модель переоценивает доход) возникают в случае, когда среднемесячные расходы клиента, согласно транзакциям, выше указанного дохода.
- Значительные отклонения вниз (модель недооценивает доход) появляются, когда среднемесячные расходы клиента по транзакциям значительно ниже среднемесячного дохода.
- Согласно пп. 3-4 модель точнее предсказывает доход для клиентов, у которых баланс расхода и дохода приблизительно совпадает. Если поведение транзакций клиента значительно отличаются от сбалансированного – предсказание ухудшается. Эту особенность модели можно применять к существующим клиентам для определения размера дополнительного дохода и/или значительного сберегательного потенциала Клиента.
- Разработанную на текущих данных по транзакциям клиентов, модель следует периодически обновлять, не раньше накопления дополнительных 10% транзакций и/или клиентов с известными доходами.
Сейчас скажете: «Банкирам хорошо - имеют озера, моря и океаны данных - анализируют себе всласть и нам на зависть». Справедливо и, потому, тороплюсь обрадовать. Похожие модели прекрасно создаются и имеют высокую предсказательную силу для:
- данных систем контроля доступа и входа в компьютерную сеть за 19 рабочих дней
- магазинов у дома и автозаправочных станций при горизонте 7 месяцев
- кафе и ресторанов при наличии чеков за 15 недель бизнес-ланчей.
А кроме дохода легко вычисляемы:
- срок повышения или предстоящего увольнения
- пристрастие к двум десяткам недешевых хобби
- состав семьи и количество иждивенцев
- увлеченность полусотней видов спорта
- дата рождения ваша и домочадцев
- наличие кошек и собак.
Что же надо, чтоб нарыть такое богатство? Предположу, что достаточно:
- настойчивости очистить информационный мусор
- желание повысить связность событий
- смелости строить гипотезы
- наглости собрать данные
- мужество ошибаться.
Желаю вам горы данных, туннели упорства, мосты предположений и долины находок. В добрый путь, охотники информационных сокровищ и рыцари мощных серверов. Не пасуйте перед огнедышащими юристами, сражайтесь с гидрами скепсиса и не бойтесь измарать сапоги в пыли полных переборов.
P.S. Так и не спросите, откуда брать эталонные значения?
Источника два:
- данные параметров коллег, запрошенные у бухгалтерии и отдела кадров
- диапазонные анкеты-опросники клиентов-добровольцев.
Так просто ;)